A novel divide-and-merge classification for high dimensional datasets |
| |
| Affiliation: | 1. Centre for Microbial Innovation, School of Biological Sciences, the University of Auckland, 3A Symonds Street, Auckland 1142, New Zealand;1. State Key Laboratory of Oncogenes and Related Genes, Division of Gastroenterology and Hepatology, Renji Hospital, School of Medicine, Shanghai Jiao Tong University, Shanghai Cancer Institute, Shanghai Institute of Digestive Disease, 145 Middle Shandong Road, Shanghai 200001, China;2. Departments of Biochemistry and Molecular Biology, University of Texas MD Anderson Cancer Center, Houston, TX 77030, USA;1. Molecular Medicine Division, Maine Medical Center Research Institute, 81 Research Drive, Scarborough, ME;2. Computational Biology and Informatics Laboratory, Perelman School of Medicine, University of Pennsylvania, Philadelphia, PA;3. Department of Medicine, Tufts University Medical Center, Boston, MA;1. BioSystems and Micromechanics IRG (BioSyM), Singapore—MIT Alliance for Research and Technology (SMART), 1 Create Way, 117543, Republic of Singapore;2. Computer Science and Artificial Intelligence Laboratory, Massachusetts Institute of Technology, Cambridge, MA 02139, USA;3. Prochem Solutions Pte. Ltd., 89C Science Park Drive, The Rutherford, # 04-13, Singapore Science Park 1, 118261, Singapore;4. Indian Institute of Science Education and Research, Kolkata, Mohanpur, West Bengal, 741246, India |
| |
| Abstract: | 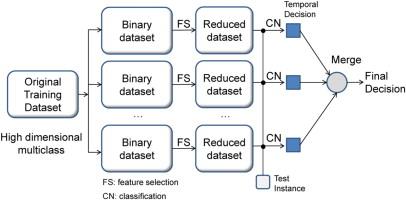
High dimensional datasets contain up to thousands of features, and can result in immense computational costs for classification tasks. Therefore, these datasets need a feature selection step before the classification process. The main idea behind feature selection is to choose a useful subset of features to significantly improve the comprehensibility of a classifier and maximize the performance of a classification algorithm. In this paper, we propose a one-per-class model for high dimensional datasets. In the proposed method, we extract different feature subsets for each class in a dataset and apply the classification process on the multiple feature subsets. Finally, we merge the prediction results of the feature subsets and determine the final class label of an unknown instance data. The originality of the proposed model is to use appropriate feature subsets for each class. To show the usefulness of the proposed approach, we have developed an application method following the proposed model. From our results, we confirm that our method produces higher classification accuracy than previous novel feature selection and classification methods. |
| |
| Keywords: | |
| 本文献已被 ScienceDirect 等数据库收录! |
|